
Comment organiser idéalement le flux de son code pour une intégration continue optimale ?
Disposer d’une chaîne d’intégration continue (CI en anglais pour Continuous Integration) est absolument nécessaire pour améliorer sa qualité logicielle et optimiser sa production. L’objectif étant d’automatiser au maximum l’exécution des tests, des linters et autres opérations optimisant la productivité (compilation, paramétrage, etc.).
Si plusieurs outils existent aujourd’hui et permettent facilement la mise en place d’une chaîne d’intégration continue (Travis et Jenkins par exemple), il faut bien avoir conscience que la richesse et les gains que vous obtenez grâce à ces outils dépendent essentiellement du flux de votre code.
Cet article a donc pour objectif :
- d’expliquer ce qu’est un flux de code,
- de présenter trois concepts (BENCH, WORKSHOP et surtout ANTIROOM) décrivant les étapes du flux de code,
- d’illustrer ces trois concepts sur des projets existants,
- de montrer où la chaîne d’intégration peut intervenir,
- et enfin d’expliquer nos préconisations.
Ainsi vous pourrez sereinement songer, si besoin, à améliorer votre chaîne d’intégration continue !
Qu’est-ce qu’un flux de code en intégration continue ?
L’intégration continue couvre toutes les opérations réalisées sur le code depuis l’espace de travail des développeurs jusqu’au dépôt stockant le code intégré. Dès lors que le code est intégré, on peut songer à construire une release (Continuous Delivery) et à passer en production (Continuous Deployment), mais ceci est une autre histoire.
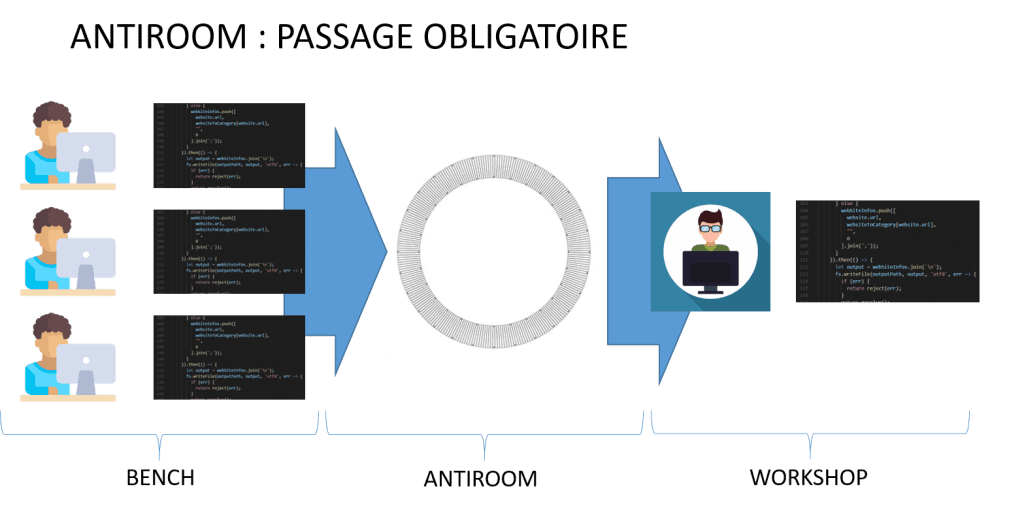
La figure suivante présente ce flux. Elle montre plusieurs développeurs qui disposent chacun de leur propre espace de travail (dans la suite de cet article nous appellerons BENCH cet espace de travail). Chaque développeur effectue donc ses modifications dans son BENCH. Toutes les modifications de tous les développeurs sont ensuite intégrées par un intégrateur pour ne former qu’un seul code intégré. Nous appellerons le WORKSHOP l’environnement de travail de l’intégrateur. Le WORKSHOP contient le code intégré.

Le flux du code en intégration continue est donc le chemin que vont prendre les modifications du BENCH vers le WORKSHOP. Ce flux doit absolument être précisé afin que l’intégration continue soit optimale.
L’ANTIROOM : un concept incontournable mais pas si connu
Pour bien comprendre le chemin que prend le code pour aller du BENCH au WORKSHOP, il faut parler de l’ANTIROOM.
L’ANTIROOM c’est le lieu où sont stockées toutes les modifications réalisées par les développeurs avant que celles-ci ne soient intégrées dans le workshop.
Autrement dit, l’ANTIROOM est le passage obligé pour que le code transite du BENCH au WORKSHOP.
La figure suivante illustre ce concept et montre bien que, grâce à ce concept d’ANTIROOM, la définition d’un flux de code nécessite de préciser deux points :
- Comment les développeurs peuvent-ils envoyer leurs modifications du BENCH vers l’ANTIROOM ?
- Comment l’intégrateur peut-il récupérer des modifications de l’ANTIROOM pour les mettre dans le WORKSHOP ?
Lorsqu’il n’y a pas d’ANTIROOM, les développeurs committent directement dans le WORKSHOP. De fait, si une erreur ou un défaut est commité celui-ci ira directement en production…
Des modèles de flux de code
Afin de bien comprendre et d’illustrer ces concepts de BENCH, ANTIROOM et WORKSHOP, voici des modèles de flux assez présents dans les projets logiciels.
Le modèle Pull-Request
Ce modèle est largement mis en avant par GitHub sur de nombreux projets OpenSource. Il considère que l’ANTIROOM contient des pull-request.
Une pull-request est proposée par un développeur. Elle contient les modifications réalisées par le développeur dans son BENCH, qu’il souhaite voir intégrées dans le WORKSHOP.
L’intégrateur peut voir les différentes Pull-Request qui lui sont proposées. Ainsi, il peut les accepter ou les refuser. Il peut même les commenter et demander aux développeurs des améliorations avant acceptation.
Notons aussi que tous les développeurs peuvent voir toutes les Pull-Request (celles des autres développeurs) et les commenter.

L’avantage de ce modèle est qu’il permet aux développeurs de bien packager les modifications qu’ils veulent soumettre. En créant une pull-request le développeur précise à l’intégrateur le bloc qu’il veut intégrer. Un autre avantage est que la pull-request est un bon support pour la revue de code. Une pull-request étant bien visible de tous les développeurs on peut alors solliciter plus facilement des revues de code.
L’inconvénient de ce modèle est qu’il laisse toute la charge de l’intégration à l’intégrateur et celui-ci peut se retrouver rapidement débordé et mettre de plus en plus de temps à accepter les Pull-Request. De plus, comme nous le verrons dans la suite, il est difficile d’intégrer des mécanismes de contrôle des pull-requests même si certains outils commencent à en proposer.
Le modèle feature branching
Ce modèle est souvent utilisé par les entreprises qui travaillent en feature team. Il considère que l’ANTIROOM est composé des branches contenant les modifications à intégrer. Ces branches sont appelées les feature branches.
La création des branches est souvent laissée à l’intégrateur. Pour autant, dans certaines entreprises, les développeurs peuvent créer les branches.
Les développeurs committent leurs modifications dans leur branche (en principe chaque développeur est affecté sur une feature et travaille donc principalement sur la branche de la feature). Enfin, quand la branche est suffisamment mature, le développeur demande à l’intégrateur de l’intégrer (merger la feature branch dans le WORKSHOP).
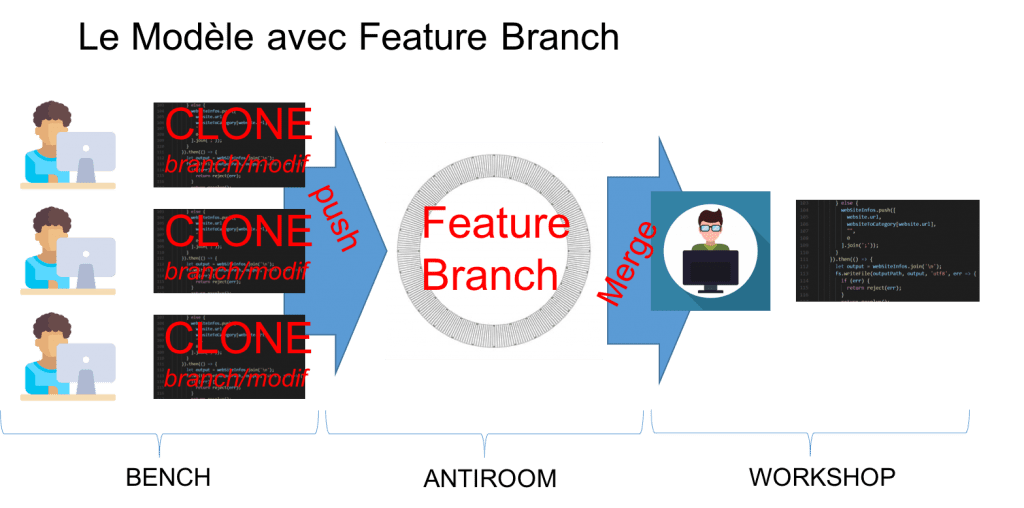
L’avantage ce modèle est qu’il soulage un peu l’intégrateur car les développeurs qui collaborent à une même feature travaillent tous sur une même branche. Ils doivent alors gérer leurs commits et les relations entre ceux-ci. L’autre avantage est qu’il est possible de réaliser des contrôles dans la feature branch et ainsi aider les déveppeurs et l’intégrateur.
L’inconvénient de ce modèle est qu’il faut faire attention à la multiplication des branches et à leur “écartement”. En effet, plus il y a de branches et plus celles-ci sont longues et différentes, plus l’intégration sera compliquée. Un autre inconvénient est que la revue de code au sein d’une même branche est un peu plus délicate à mettre en place.
Le modèle Push to Master (Google)
Ce modèle est plébiscité par Google. Il considère que l’ANTIROOM est la branche principale du dépôt (oui, il s’agit bien de la branche master !!!).
De fait, tous les développeurs peuvent envoyer leurs modifications dans l’ANTIROOM “simplement” en commitant et en pushant sur la branche master. Enfin, ce n’est pas si simple que cela car, nous le verrons dans la suite de l’article, il y a de nombreux contrôles.
L’intégrateur, quand il le souhaite, peut intégrer certaines modifications dans le WORKSHOP en réalisant du cherry picking. Bien souvent le WORKSHOP est composé de plusieurs branches, différentes de la branche Master. L’intégrateur sélectionne donc les commits réalisés sur la branche master et les ajoute dans la branche d’intégration désirée.
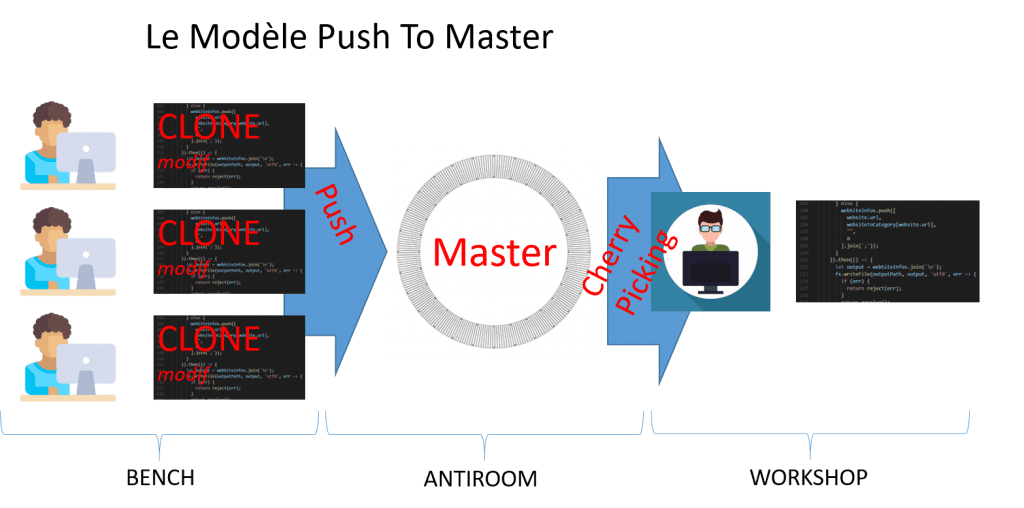
Ce modèle, qui peut sembler un peu bizarre, a le principal avantage de faire en sorte que tous les développeurs aident à l’intégration. Ils sont tous responsables de la qualité du dépôt master !!! L’autre avantage c’est que tous les développements en cours sont à jour. Fini les incohérences découvertes lors de l’intégration… tardive. Enfin, avec ce modèle il est possible de réaliser dans l’ANTIROOM exactement les mêmes contrôles que l’on pourrait faire dans le WORKSHOP.
L’inconvénient réside essentiellement dans la complexité de sa mise en oeuvre et dans… la résistance au changement. En effet peu d’organisation accepteraient aujourd’hui de passer à ce modèle. Google le fait depuis de nombreuses années.
Les modèles hybrides
Il existe de nombreux modèles hybrides basés sur les modèles que nous venons de présenter.
Par exemple, dans plusieurs projets on couple un feature branching avec des pull-request. Les développeurs travaillent sur des feature branch et construisent des pull-request à partir de celles-ci. On peut alors considérer qu’il y a deux ANTIROOM l’une après l’autre (feature branch puis pull-request).
Pour le développement du noyau de linux, on a d’abord un modèle de pull-request vers les WORKSHOP gérés par des développeurs reconnus. Ensuite ces développeurs fonctionnent sur un modèle par feature branching avec le WORKSHOP de linux, géré par Linus Torvalds.
Ce deux exemples ilustrent un peu la diversité des organisations et de leur flux de code.
Quand intervient la chaîne d’intégration continue ?
Une chaîne d’intégration continue bien définie peut intervenir aux trois niveaux de notre modèle :
- BENCH : En intégrant des contrôles dans le BENCH il est possible de signifier au plus tôt l’impact des modifications réalisées par un développeur sur l’application qu’il développe. Ces contrôles peuvent se faire lors de l’édition du code (dans l’IDE) ou lors de l’envoi des modifications vers l’ANTIROOM. Pour autant, il est important de noter que l’ensemble des contrôles réalisables sur le BENCH est souvent très limité car le BENCH ne dispose pas de toutes les informations nécessaires à leur réalisation. De plus les contrôles réalisés sur le BENCH ne porte que sur les modifications réalisés par un développeur et pas sur l’impact de ses modifications sur les modifications en cours par les autre développeurs.
- ANTIROOM : En intégrant des contrôles dans l’ANTIROOM on peut faciliter grandement le travail de l’intégrateur et même demander aux développeurs d’effectuer des améliorations sur leurs modifications. Ces contrôles peuvent se faire automatiquement (analyse de commit ou de pull-request) ou même impliquer d’autre développeurs (revue de code). Nous le verrons dans nos préconisations, nous conseillons de multiplier les contrôles à ce niveau.
- WORKSHOP : Tous les contrôles peuvent être réalisés dans le WORKSHOP. C’est d’ailleurs là qu’ils sont principalement réalisés, et, qu’en cas d’erreur, des notifications sont remontées vers les différents participants du projet. Pour autant, c’est aussi le moment le plus tardif pour réaliser un contrôle !
On se lance… voici nos préconisations
Notre première préconisation est de se rapprocher d’un flux proche du push to master !!! Celui-ci réduit l’écart entre développeur et intégrateur. Il facilite grandement l’intégration et permet ainsi d’optimiser la chaîne d’intégration continue. A ProMyze nous avons vécu les limites du modèle par pull-request et du feature branching. Ces modèles, même s’ils sont intéressants, offrent moins d’avantage que le push to master.
Notre deuxième préconisation est de faire remonter au plus tôt tous les contrôles possibles. S’il vous est possible de faire remonter un contrôle dans le BENCH faites le. Sinon, faites tout pour les intégrer dans l’ANTIROOM. Avec un modèle push to master il est très facile d’effectuer tous les contrôles à ce niveau.
En allant plus loin on peut préciser où il serait préférable de faire quels contrôles :
- Test unitaire : Idéalement il faut pouvoir faire les tests unitaires dans le BENCH. Après, il faut pouvoir les rejouer soit dans l’ANTIROOM soit dans le WORKSHOP.
- Test d’intégration : Impossible à réaliser dans le BENCH, il faudrait pouvoir les faire dans l’ANTIROOM, sinon dans le WORKSHOP.
- Test de validation E2E : Là encore, idéalement dans le BENCH ou dans l’ANTIROOM.
- Dette technique : Grâce aux linters intégrés dans l’IDE on peut faire un contrôle dans le BENCH. Après, il faut pouvoir faire un contrôle plus fin dans l’ANTIROOM.
- Revue de code : Clairement dans l’ANTIROOM.
Une autre question est de savoir si vous souhaitez effectuer des contrôles bloquants ou non-bloquants. Par bloquant on veut dire que si on ne passe pas le contrôle alors le code est bloqué dans le flux et ne peut pas aller plus loin. Par non bloquant on considère que le code avance dans le flux même s’il n’a pas passé les contrôles. Nous considérons que les tests peuvent être bloquant alors que les contrôles de dette technique ou de qualité (couverture de ligne de code) devraient être non bloquant.
Enfin, notre dernière préconisation est au coeur de l’engagement dans notre société ProMyze : faites des retours personnalisés. Les contrôles doivent uniquement porter sur les modifications réalisées par les développeurs et pas sur l’intégralité de l’application. Si un développeur modifie une ligne, il faut contrôler cette ligne et pas plus. C’est dans cet objectif que notre outil Themis a été conçu, quelque soit le modèle de flux que vous avez choisi.
Allons plus loin ensemble
Cet article vous a plu, vous a interpelé, vous voulez nous faire part de votre expérience sur un modèle de flux de code, n’hésitez pas à réagir. Nous ne prétendons pas avoir “la science infuse”, loin de là. Notre objectif est plutôt de participer à une discussion générale sur les différents environnements de développement, leurs avantages et leurs limites.